
Student: Yannick Rößling
Supervisor: Andreas Bott
Time period: 04/01/2021 - 07/01/2021
Type: Bachelor Thesis
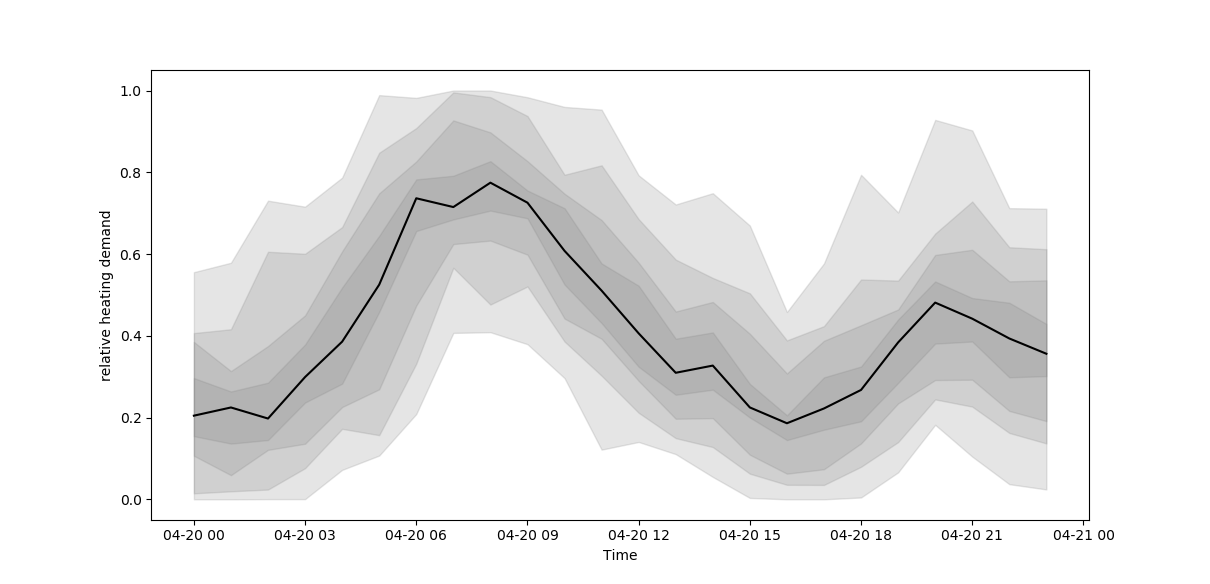
Im Zuge der Energiewende stellt der Wärmesektor als größter Endenergieverbraucher ein immer wichtiger werdendes Handlungsfeld dar. Wärme ist vergleichsweise einfach und kostengünstig speicherbar. Eine Elektrifizierung der Wärmeerzeugung zusammen mit dem flexibleren Betrieb von Fernwärmenetzen verspricht daher sowohl eine CO2-reduktion im Wärmesektor, als auch Flexibilität im Stromsektor um auf schwankende Einspeisung aus erneuerbaren Quellen reagieren zu können.
Die Grundlage für eine flexiblere Wärmeerzeugung sowie die Bewertung damit verbundener Potentiale sind Standardlastverläufe, wie sie beispielsweise in der VDI-4655 definiert sind.
In dieser Arbeit sollen reale Verbrauchsdaten aus dem Fernwärmenetz Darmstadt Nord statistisch untersucht und mit Standartlastverläufen verglichen werden. In einer explorativen Datenanalyse soll die Varianz der Lastverläufe für verschiedene Tage und Verbraucher mit den Abweichungen zu den entsprechenden Standartlastverläufen verglichen werden und eigene Standartlastverläufe für neue Verbrauchertypen entwickelt werden.
Student: Imed Tayeche
Supervisor: Mario Beykirch
Time period: 08/05/2020 - 02/05/2021
Type: Master Thesis
Im Rahmen des Projektes EnEff Campus wird ein medienübergreifenden Energiemonitoring aufgebaut, um eine umfassende Abbildung des Energiesystems zu erstellen. Diese Abbildung, auch digitaler Zwilling genannt, soll genutzt werden, um den Betrieb des Energiesystems zu optimieren. Die dafür notwendigen großen Datenmengen müssen jedoch zuverlässig erfasst werden. Da diese Daten von einer großen Anzahl Messstellen mit einer hohen zeitlichen Frequenz aufgenommen werden, müssen die Daten automatisiert auf Plausibilität geprüft werden. Unplausible Werte können so von den Modellen ignoriert werden.
Ein Problem bei der Plausibilitätsprüfung von Lastdaten ist, dass sie starken saisonalen und exogenen Einflüssen unterliegen. Beispielsweise kann eine hohe Wärmelast an einem Wintermorgen plausibel sein, an einem Hochsommernachmittag wiederum unplausibel. Diese Einflüsse sollen bei der Plausibilitätsprüfung berücksichtigt werden, indem eine probabilistische Wärmelastprognose erstellt wird und die Messwerte mit dieser verglichen werden. Aus den Wahrscheinlichkeitsverteilung für die Wärmelast kann dann eine auch eine Wahrscheinlichkeit für die Korrektheit der gemessenen Werte bestimmt werden.
Ziel dieser Arbeit soll es sein, eine automatisierte Plausibilitätsprüfung für thermische Lastdaten zu erstellen. Diese soll auf einer probabilistischen Wärmelastprognose basieren. Aus den Unsicherheitsintervallen der Prognose soll dann die Wahrscheinlichkeit bestimmt werden, dass ein gemessener Wert korrekt ist.
Student: Mario Francisco Dongarra Trave
Supervisor: Edwin Mora
Time period: 12/01/2020 - 04/30/2021
Type: Bachelor Thesis
The integration of decentralized energy resources into power distribution systems requires novel control strategies in order to guarantee feasible system operation at all times. In this bachelor thesis, a recently developed robust power flow control algorithm should be applied to determine optimal control actions for a set of coupled distribution networks based on the information provided by a small number of sensors, that are subject to uncertain generation/consumption profiles. The improved resilience and performance of the combined system shall be validated systematically through simulation experiments using networks of different complexity.
Student: Moritz Wermann
Supervisor: Martin Pietsch
Time period: 11/11/2020 - 04/12/2021
Type: Bachelor Thesis
There are different approaches to implement and solve optimization problems. The choice of possible software combinations is wide, using for example GAMS, Pyomo, Pulp, YALMIP. Objective of this thesis is a comparison of different software combinations and libraries. For this purpose, a specific problem of sequential distribution grid restoration will be implemented in different development environments. Criteria such as performance, complexity, accuracy, extensibility and usability of optimization problems will be examined in the context of this thesis.
This project seminar is addressed to bachelor students.
Student: Jiali Huang, Aaron Hebing
Supervisor: Martin Pietsch
Time period: 11/09/2020 - 03/31/2021
Type: Project Seminars Bachelor
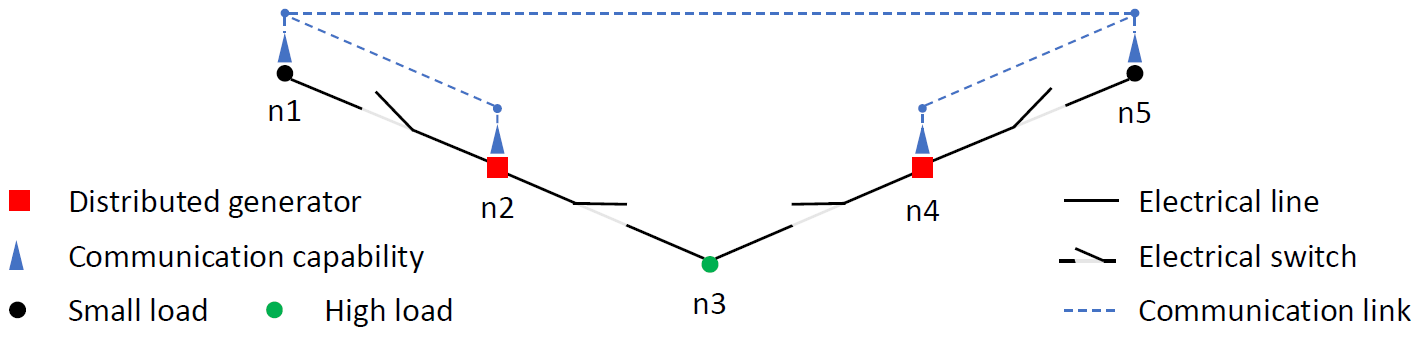
The LOEWE center emergenCITY aims at investigating fundamentals, methods and solutions towards the resilience of future digital cities. More specifically, EINS addresses the interdependence of ICT and water supply on electricity supply. In order to make these interdependencies visible and to visualize suitable algorithms and heuristics in their application, a demonstrator will be developed. This will be organized in cooperation with the Chair of Fluid Systems (FST) from the Department of Mechanical Engineering. The entire demonstrator is intended to react dynamically to external forces to the system and to compensate these disturbances by applying resilient control schemes. The primary focus of this project seminar is the conceptual design and construction of the demonstrator, which will consist of modular elements for a cable-based communication grid, a DC-based power grid and the water grid.
Your tasks:
- Make yourself familiar with decentralized networks as well as sensor and control units
- Development of a metric for the evaluation of the resilience of water and energy grids
- Technical concept and construction of the demonstrator
- Documentation and presentation of the results
Team of 2-3, knowledge of energy management, good programming skills, independent- structured and careful work
We offer:
- Working in an interdisciplinary team with students, HiWis and scientific staff
- If you are interested and motivated: possible HiWi-Job afterwards
Student: Jonas Seng
Supervisor: Jonas Hülsmann
Time period: 03/01/2021 - 08/03/2021
Type: Master Thesis
Energiesystemmodelle finden so-wohl in der täglichen Einsatz-planung als auch der langfristigen Ausbauplanung Einsatz. Modelle reichen von einzelnen technischen Anlagen bis zu komplexen Erzeuger-/ Verbrauchernetzwerke auf (inter-)nationaler Ebene. Bereits kleine Modelle können trotz ihres mathematisch simplen Aufbaus komplexe Zusammenhänge abbilden und sich daher dem Verständnis von nicht-Expertenentziehen. Häufig sind es jedoch solche nicht-Experten (z.B. Manager, Politiker oder Bürger), die auf Grundlage der Modellergebnisse wichtige Entscheidungen treffen müssen. Entscheidungen können von der Auslegung der eigenen Heimerzeugung, über den Bau neuer Großkraftwerke, bis hin zur Subventionierung gewisser Energietechnologien (Synthetische Kraftstoffe) reichen.
Da mit einer Fehlentscheidung oft ein persönliches Risiko einhergeht, ist es wichtig, dass Entscheider die Implikationen, die mit einem Energiesystemmodell einhergehen, verstehen. Hierzu kann es sinnvoll sein das Modell in ein anderes, einfacher verständlicheres Modell zu überführen, beispielsweiße einen kausalen Graphen. Bei einem kausalen Graphen handelt es sich um einen gerichteten Graphen, dessen Kanten die Beziehungen von Variablen in einem System abbilden.
Um solche kausalen Graphen aus Daten zu extrahieren gibt es bereits verschiedene Algorithmen [1], welche als Teil dieser Master/Projektseminararbeit implementiert werden sollen. Die implementierten Algorithmen sollen anhand bekannter Datensätze (z.B. aus dem Bereich der Bioinformatik [2]) validiert werden und dann auf neue Daten von Energiesystemmodellen angewendet werden.
Folgende Voraussetzungen sollten erfüllt sein:
Programmierkenntnisse (vorzugsweise Python)
Besuch der Veranstaltung Machine Learning and Energy oder Energiemanagement und Optimierung sind hilfreich
Student: Richard Säuberlich
Supervisor: Christopher Ripp
Time period: 11/01/2020 - 01/31/2021
Type: Bachelor Thesis
Ziel dieser Arbeit ist die voll funktionsfähige, softwareseitige Entwicklung eines MBus-Splitter. Das einzige auf dem Markt verfügbare Produkt mit dieser Funktionsweise wurde bereits erfolgreich im Labor getestet, ist jedoch sehr teuer. Die Eigenentwicklung soll daher deutlich günstiger werden. Um die Bearbeitung auf 3 Monaten zu begrenzen wird als Hardwarebasis einen Raspberry als Mikrocontroller, einen USB Pegelwandler (MBus Master) sowie einen M-Bus zu TTL USB Adapter (MBus Slave) verwendet. Die Entwicklung eigener Platine für den Pegelwandler sowie für MBus zu TTL wird dabei von der Arbeit ausgenommen. Der Schwerpunkt dieser Arbeit beschränkt sich somit auf die Entwicklung der geeigneten Software.
Student: Igor Binsfeld
Supervisor: Christopher Ripp
Time period: 07/06/2020 - 01/06/2021
Type: Master Thesis
Im Rahmen dieser Arbeit soll der Einfluss von CO2 Preisen, unter Einfluss verschiedener Kalkulationsmethoden von CO2 Intensitäten, auf den Betrieb eines realen Energiesystems untersucht werden. Dabei werden von GGEW die Daten eines realen Wohnquartiers zur Verfügung gestellt. Data obtained from Mr. Glotzbach (GGEW)
Student: Sebastian Perle
Supervisor: Mario Beykirch
Time period: 06/07/2021 - 09/08/2021
Type: Bachelor Thesis
To generate reliable forecasts of the thermal load of a building it is important to understand the dynamics that effect its heat load. Unfortunately, it is mostly not feasible to simulate an existing building in detail since this would require extensive knowledge about actual building parameters such as thermal transmittance of all the building parts. However, a building can be abstracted as a simple closed thermodynamic system that exchanges heat with the environment e.g. in the winter it loses heat to the environment, while gaining heat from the heat grid and solar radiation. This model would only have few unknown parameters which could be inferred from measured heat load and weather data.
The goal of this Bachelor Thesis is to learn a simple thermodynamic model of a building based on available data from the campus Lichtwiese using Bayesian inference methods. The data basis will be heating data of the last 3 years as well as estimated building parameters. This thesis will contribute to the research project “EnEff: Campus Lichtwiese” which aims to improve energy efficiency on the campus by creating a digital twin of the campus energy system.
Student: Mohamed Ghanmi
Supervisor: Tim Janke
Time period: 11/02/2020 - 05/03/2021
Type: Master Thesis
Probabilistic forecasts improve over classic point forecasts by issuing a predictive distribution instead of only predicting the expected value. However, this is not sufficient for risk-sensitive optimal decision making in the case of a multivariate target variable. In this case, sampling directly from the marginal predictive distributions would not yield a realistic dependency structure for the multivariate samples. Here, copulas can be used to generate samples with a coherent multivariate dependency structure from arbitrary continuous marginal distributions. Typically, the employed copulas belong to a parametric family (e.g. Gaussian copulas) and are assumed to be stationary, i.e. the dependency structure of forecast errors is assumed to be independent and constant while the predictive marginal distributions are dependent on the covariates.
The goal of this thesis is to investigate if it is possible to improve the quality of multivariate probabilistic forecasts by learning implicit conditional copulas using implicit generative models, e.g. generative neural networks or by learning a model to dynamically parametrize known copulas.
Student: Lucas Steinhäuser
Supervisor: Tim Janke
Time period: 10/12/2020 - 04/11/2021
Type: Master Thesis
In the course of the energy transition new types of loads, e.g. electric vehicle chargers, and generators, e.g. PV plants, became more common in low voltage distribution grids. This makes state estimation for those networks more difficult but also more important. One possible remedy is to install new sensors in the gird. However, this can be quite costly. Here, statistical methods offer an interesting alternative. The goal of this thesis is to develop an approach for disaggregating the measured load flow of simulated low voltage distribution grids which allows to realibly estimate the underlying signals from loads and generators. The thesis is done in cooperation with the PSI AG.
Student: Khalil Tounsi
Supervisor: Tim Janke
Time period: 03/15/2021 - 09/14/2021
Type: Master Thesis
The traditional local approach to forecasting groups of (related) time series is to fit separate models to every single series, i.e. these models share the same functional form but a different parameter set is learned per time series. The global approach considers all series as the same regression task, i.e. only a single function is fit to all series. This results in larger parameter efficiency and allows to fit more complex functions. Empirical evidence suggests that the global approach often outperforms the local approach.
This thesis aims to empirically compare the local and the global approach to probabilistic heat demand forecasting using data from the TU Darmstadt Lichtwiese campus. The thesis builds on previous work on probabilistic heat load forecasting for the same data set.
Student: Rikesh Joshi
Supervisor: Edwin Mora
Time period: 02/01/2021 - 04/30/2021
Type: Bachelor Thesis
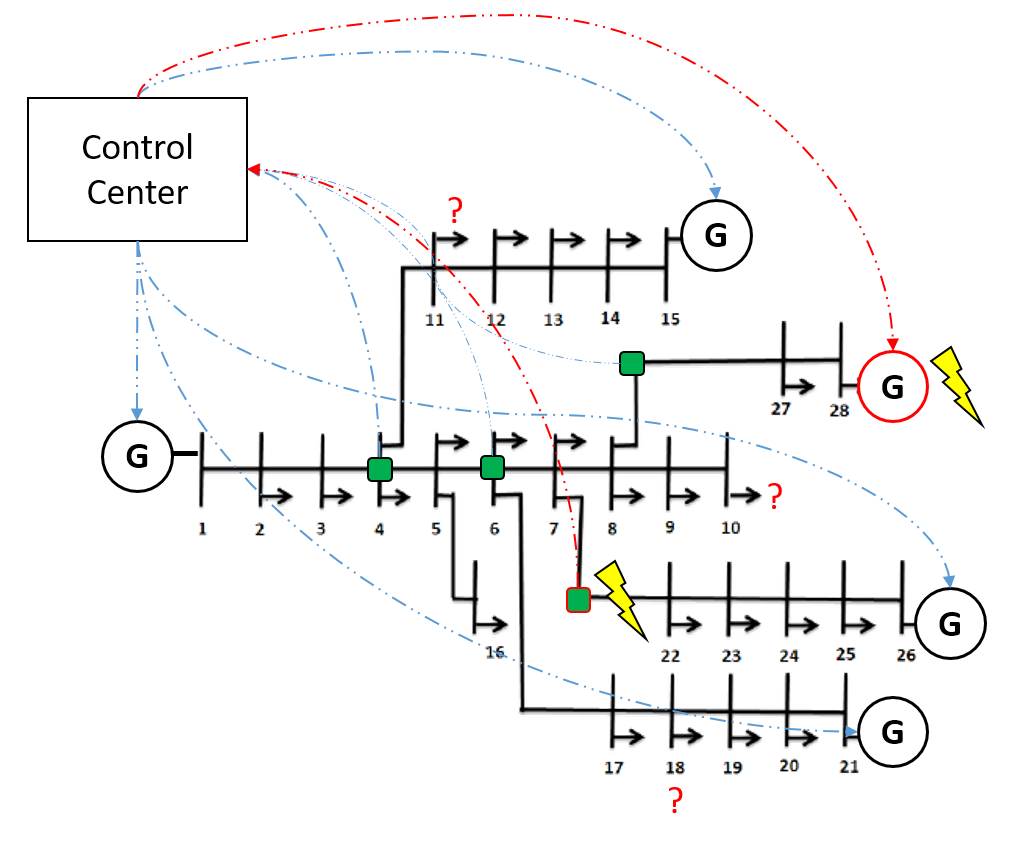
Extending recently proposed ideas regarding minimal robust power flow control, this thesis aims to determine the smallest number of actuator and sensor devices required to guarantee secure grid operation, even with contingencies involving the loss of a small number of transmission lines. Given a linear power flow model and a fixed set of actuators and sensors, an optimization algorithm should be first implemented to check if there exists a suitable affine-linear control law for those sets tolerating the loss of a few transmission lines. The obtained algorithm should be then used as a subroutine to find the minimal number of actuator and sensors. The resulting optimization tool should be then tested with electrical power grids of different complexity. Finally, the minimal actuator and sensor sets shall be validated on a non-linear version of the power flow equations.
Student: Felix Hüttl
Supervisor: Edwin Mora
Time period: 09/15/2020 - 03/14/2021
Type: Master Thesis
Student: Lasse Schöfer
Supervisor: Tim Janke
Time period: 10/01/2020 - 03/31/2021
Type: Master Thesis
Large telecommunication infrastructure facilities have a substantial demand for electricity. A large share of this demand is attributable to the cooling of the hardware. While the load on the hardware is relatively constant and inflexible, it is possible to shift some of the cooling demand either by using storage or by cooling down the facility as a whole at certain times. Thereby, the expenditure for electricity could be reduced by shifting a part of the demand to low price hours.
This thesis aims to investigate the possible savings from such strategies for several facilities of the Deutsche Telekom AG. The student should develop a flexible tool to analyze the potential savings for the different facilities under optimal scheduling using known historical prices and load curves.
Prospective students should have some prior experience in numerical optimization.
This thesis will be done in close cooperation with Deutsche Telekom AG/PASM GmbH.
Student: Michael Heise
Supervisor: Martin Pietsch
Time period: 11/23/2020 - 05/24/2021
Type:
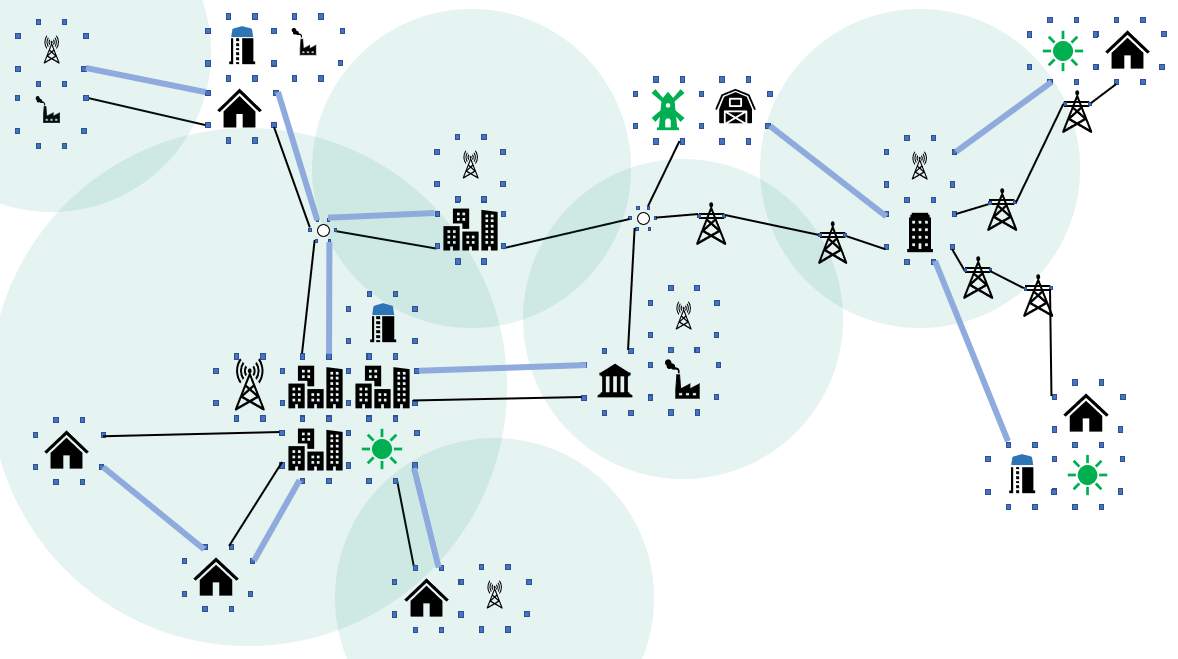
In order to compensate the loss of communications in crisis situations, new approaches, as the deployment of UAVs are developed. Regardless of the specific UAV technology, their usage raises the question of optimized energy supply and positioning in the cities landscape. Disruptions in the distribution grid effect all parts of urban infrastructure, especially ICT. Even though most of the ICT is capable to withstand short outages, longer outages are out of cope. In order to compensate the loss of communications in crisis situations, new approaches, as the deployment of UAVs are developed. Regardless of the specific UAV technology, their usage raises the question of optimized energy supply and positioning in the cities landscape.
Student: Nicole Goad
Supervisor: Mario Beykirch
Time period: 08/24/2020 - 02/24/2021
Type: Master Thesis
Residential thermal energy consumption accounts for a significant part of the overall energy consumption and it is therefore important to have information about the energy demand before the construction of a new building. While we have access to extensive engineering models to determine the demand of buildings these models are complex, need detailed input data and don’t take uncertainties (e.g. user behavior) into account. Furthermore, a more detailed hourly estimation of the thermal energy demand of a building can be used to select appropriate district heating infrastructure, such as a communal thermal power station. Low energy buildings are an especially interesting research subject as their share in existing buildings will increase in the future due to regulations which aim to reduce residential CO2 emissions. An important question for the planning of infrastructure is, whether a communal heating infrastructure is advisable for a quarter with mostly low or ultra low energy buildings.
The goal of this work is to estimate a buildings thermal energy consumption based on historical consumption data, building location and building parameters. This should include a probabilistic demand estimation which takes uncertain user behavior into account.
Student: Julian König
Supervisor: Andreas Bott
Time period: 10/01/2020 - 04/01/2021
Type: Master Thesis
Industrielle Energiesysteme werden zunehmend komplexer und sollen dabei im Zuge der Energiewende mit maximalem Wirkungsgrad betrieben werden. Eine Möglichkeit dies zu erreichen, ist der Einsatz von Algorithmen zur Betriebsoptimierung. Die stochastische Natur realer Energiesysteme erschwert den Optimierungsprozess jedoch enorm. Gewählte Betriebsstrategien müssen robust gegenüber stochastischen Einflüssen sein, sodass die kritische Energieversorgung in jedem Fall gewährleistet werden kann. Genau dieses Problem wird durch Methoden der robusten Optimierung adressiert. Um den praktischen Einsatz dieses Verfahrens zu evaluieren, soll im Rahmen einer Masterarbeit ist ein Wärmeversorgungssystem aus der ETA-Fabrik (BHKWs, Speicher, Verbraucher) als robustes Optimierungsproblem modelliert werden. Anschließend ist der Betrieb des realen Wärmeversorgungssystems durch das aufgestellte Modell zu optimieren. Diese Versuche sind dann die Grundlage einer Bewertung des robusten Optimierungsverfahrens.
Arbeitspakete:
- Literaturrecherche zur robusten Optimierung von Energiesystemen
- Formulieren eines robustes Optimierungsmodells für das Wärmeversorgungssystem
- Optimieren der Betriebsstrategie des Wärmeversorgungssystems in der ETA-Fabrik
- Bewertung des Verfahrens hinsichtlich Lösbarkeit, Optimalität und Robustheit
Student: Christian Galda
Supervisor: Martin Pietsch
Time period: 04/15/2021 - 09/14/2021
Type: Bachelor Thesis
In order to enable the participation of citizens during crisis situations, one mission of the novel emergenCITY center develops a virtual platform that enables citizens to self-organize. We want to investigate how such a platform could be used for supplying limited amounts of electricity from decentral sources in such emergency situations.
For improving life during power outages this thesis shall develop a web based platform for neighborhoods that share a common subsection of the electric grid. Disconnected from the main grid, decentralized resources can form local microgrids in such grid sections. Knowing that the total amount of power production is typically not sufficient to supply all loads, citizens are to determine a schedule for their most urgent power needs, in a discrimination free-way. To obtain demand side flexibility we can assume the existence of many smart home devices that are externally switchable.
The planned work comprises the development of a backend for the platform as well as a web-based user frontend. It also includes the formulation of the underlying resource allocation optimization problem and an evaluation of all elements with simulated scenarios.
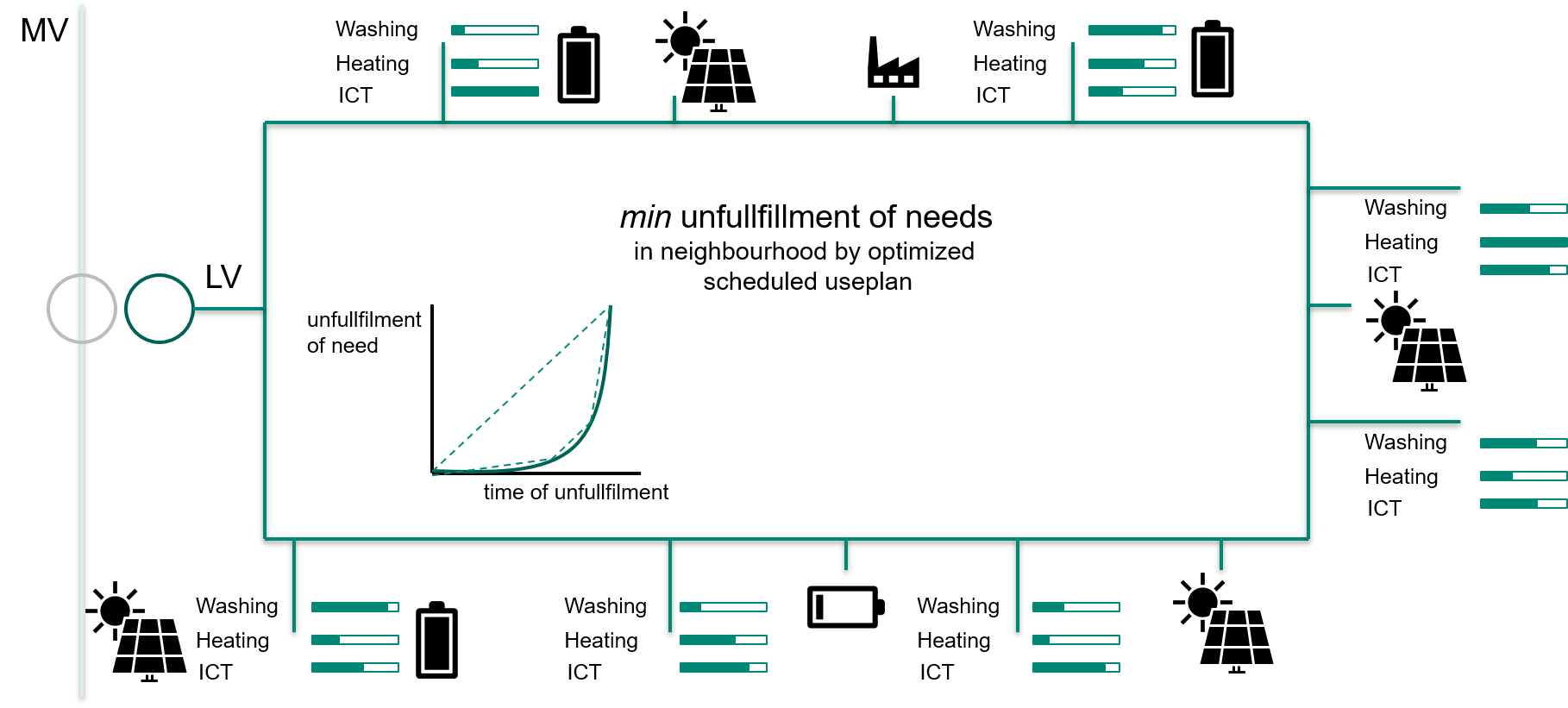
Student: Rene Prinz
Supervisor: Allan Santos
Time period: 11/01/2020 - 05/01/2021
Type: Project Seminars Bachelor
The goal of this project seminar is to develop a simulation environment for smart grid communication networks. Given a pool of communication technologies, e.g. digital subscriber line (DSL), power line communication (PLC), and cellular, the environment should provide an easy-to-use interface for deploying networks with varied topologies. Also, it should be possible to run arbitrary processes in the network’s nodes to simulate smart grid functionalities.
Student: Rachel Maier
Supervisor: Christopher Ripp
Time period: 07/23/2020 - 01/22/2021
Type: Master Thesis
Die Arbeit soll mehrere Ziele im Themenfeld der Zeitreihen-Aggregation in Kombination mit der Implementierung von Speichern und Sektorkopplung verfolgen:
- Zeitreihen-Aggregation zur Speicherimplementierung
- Überarbeitung der bestehenden heuristischen Zeitreihen-Aggregation für die Einsatzplanung hin zu einer datengestützten Zeitreihen-Aggregation
- Implementierung einer effizienten Zeitkopplung für die Abbildung von Speichern
- Bildung eines Indikators zur Bewertung der Kritikalität extremer Perioden in der Zeitreihen-Aggregation
- Erweiterung von Speichern und Sektorkopplung im GAMS-Optimierungsmodell
Das erste Ziel der Arbeit ist die Implementierung einer datengestützten Zeitreihen-Aggregation sowie eine rechenzeit-effiziente Implementierung von gekoppelten Variablen zur Abbildung von Speichern. Dies soll die Übertragbarkeit des Energiemodells auf verschiedene urbane Systeme mit unterschiedlichen Potenzial- und Nachfrageprofilen erhöhen.
Kooperation mit Greenventory eine Ausgründung des Fraunhofer ISE
Student: Johannes Sindt
Supervisor: Allan Santos
Time period: 09/15/2020 - 03/15/2021
Type: Master Thesis
Suppose you are planning a hybrid power plant consisting of a photovoltaic (PV) plant, a battery and backup diesel power to supply a given electric load at a defined remuneration per delivered kWh. During the planning stage, the exact PV production will not be known (only its distribution). The required amount of diesel to cover the demand at times with no or little sun will thus also be uncertain. The same applies to the profit of the plant which is determined as acquired remuneration minus the fuel cost for the diesel. Projects with highly uncertain profits, however, can only obtain financing at high interest rates. If we could quantify and bound the uncertainty in more detail, one would be able to acquire cheaper financing and thereby greatly improve the economic viability of such a project. In sum, exact and efficient uncertainty quantification methods could thus help to move forward the energy transition towards a low carbon society. Mathematically, the plant operation can be described as a linear program (LP), with the solar power availability determining the right hand side of the boundary conditions. Assuming a (multivariate) Gaussian distribution for possible PV timeseries, the task is to determine the distribution of the linear program’s optimal values (or parameters of it). It seems that such random LPs have not been considered before. Prekopa [1966] investigated random LPs in which the optimal basis does not change. The following approaches should be investigated:
• It might be easier to investigate the dual program in which the objective coefficients are random, but everything else is fixed.
• For a given basis, one needs to estimate the probability that this basis is optimal.
• Varying the right hand side or objective coefficients yields a decomposition of the space into polyhedra on which a certain basis is optimal.
• In two dimensions, the computation might be possible analytically.
• In general, one needs to estimate this probability, e.g., using sampling.
• Then the (relevant) bases should be enumerated.
• Possibly, one can start with a uniform distribution (cubes) and then generalize to ellipsoids and normal distributions.
This is a cooperation thesis with research group optimization of the department of mathematics.
Student: Isabella Grieser
Supervisor: Allan Santos
Time period: 05/01/2021 - 11/01/2021
Type: Project Seminars Bachelor
In the context of network virtualization, the virtual network embedding (VNE) problem consists of mapping interconnected functional blocks, so-called Virtual Network Requests (VNR), onto physical communication networks, the substrate networks (SN). VNE is a widely studied problem and several algorithms have been proposed in the last years. The goal of this project seminar is to extend a recent algorithm for VNE to the Virtual Power Plant (VPP) formation problem. In a commercial VPP, several Distributed Energy Resources (DER) are logically aggregated and are controlled by the VPP coordinator. DERs using solar and wind energy have a highly variable and not-fully predictable power output, which can cause the VPP to not meet agreed generation. Based on the reliability paradigm of the considered algorithm and given the probability distribution of the DERs’ power output, it is possible to guarantee with a certain reliability that the VPP will indeed output at least the agreed power with minimal cost.

